

AIと「笑い」~AIは漫才ができるか?

【AIに「笑い」を作り出すことはできるか。AIによる「漫才台本」の自動生成の研究が進んでいる。AIが作った漫才はどんなものだろう】
灘本 明代(甲南大学知能情報学部教授)
はじめに
OpenAI[1]が2022年11月に公開したChatGPT[2]に代表されるように生成AIのブームが起きている。それ以前から生成AIの研究はあったが、ChatGPTの生成の精度の高さに研究者は驚くと共に、急速に一般に普及していっている。様々な分野において生成AIの利活用が期待されているが、本稿では「笑い」という視点からの生成AIについて述べてゆきたい。
生成AIとは
「笑い」の視点から生成AIを語る前に、生成AIについて簡単に述べたいと思う。
生成AIは簡単に言うとAIの技術で様々なコンテンツを生成することである。ここでいう様々なコンテンツとは、テキスト、画像、動画、音楽等を指す。この生成AIの内、今回はテキストの生成AIについて述べる。
現在、テキストの生成AIはルールベース、深層学習を用いたもの等様々な手法があるが、現在注目されているのは深層学習を用いたものである。さらに深層学習を用いた生成AIの手法も多数あるが、その中で注目したいのはTransformer[3]という技術である。
Transformerは転移学習という技術がベースとなっており、転移学習の学習方法は事前学習とファインチューニングの2段階に分かれている。
この2段階の学習方法は学習効率をよくすることを目的としており、事前学習では一般的な基礎知識を学習するのが一般的である。例えば,Wikipediaで学習することにより、一般的な基礎知識を与え、そのあと学習したい分野(ドメイン)に特化したデータでファインチューニングにより学習するといった感じである。
Transformerはこの転移学習をベースに新たにAttentionという技術を入れたものであり、Attentionとは、簡単にいうとテキスト(文やフレーズ)の中の単語(やフレーズ)の意味を理解するのにどの単語(やフレーズ)に注目すればいいのかを示すスコアまたはそれを出す機構の事である。
このAttentionによりTransformerは高精度な生成結果を実現している。そして、ある単語(またはフレーズ)の次に来る単語(またはフレーズ)を学習により予測するものである。
詳細は様々な文献がすでに多数あるので、それを参考にしていただきたい。
「笑い」とは何か?
「笑い」とは何かを考えたことがあるだろうか?「笑い」は日常的でもあり、そうでない場合もある。
人々は様々な困難に直面すると、不安や緊張を感じることがある。このような心理的な負担を和らげるために、笑う事が有効であることが知られている[4]。
医学的にも、笑う事で体に悪影響を及ぼす物質を攻撃してくれるリンパ球の一種であるナチュラルキラー細胞の働きが活発になり、免疫力がアップするという報告が多数されている[5]。
また、がんになったその後を生きていくうえで直面する課題を乗り越えていくための支援システムであるサバイバーシップ支援においても、患者の心理的な負担を和らげるために笑いが有効であることが知られている[6][7]。
さらに、笑いで患者の自己治癒力を高めたり、または笑いにより病気の予防をサポートする事を目的とした笑い療法士[8]がおり、医療・福祉の現場で活躍している。また,笑いを対象とした市民参加型の学会である日本笑い学会もあり、活発な活動を行っている[9]。
一方、人はなぜ笑うかは永遠の課題であるが、人が笑うメカニズムにおける代表的なものとして、優越感を得たときに人は笑うという「優越理論」、予期したことが現実にはそうならなかった場合の不一致が笑いを引き起こすという「不一致理論」、高まった緊張が不要となったときに笑いによって解放される「開放理論」などがある[10]。また,安部達雄は「おかしみの構造」[11]を提案し、笑い(おかしみ)は概念のはき違いから起こるものであると定義している。
さらに、情報学(コンピュータ・サイエンス)の視点から「笑い」をみると、様々な人々が情報学の領域において笑いを対象とした研究を行っている。
例えば,AIによる大喜利の生成[12]や、ユーモアのある対話システム[13]、ロボットによるユーモア対話[14]等様々な研究がある。その中で甲南大学知能情報学部の灘本、北村、梅谷(以下、我々)は日本固有の笑いのコンテンツである「漫才」に着目し、漫才台本自動生成の研究を行っている。次章でこの漫才台本自動生成の研究について紹介してゆきたい。
漫才台本自動生成
まず思い浮かべるのは、「ChatGPTで漫才台本は自動生成できるのか?」である。
ChatGPTは進化しているので、2023年9月現在では、答えは「できない」である。ChatGPTはプロンプトと呼ばれる入力単語(またはフレーズ)によって結果がかわるが、お題+漫才を作ってというプロンプトを入れてみる。例えば「大谷翔平について漫才を作って」とプロンプトに入れると、図1のように漫才のような対話は作るがよく見るとボケていないのがわかる。

なぜChatGPTはボケないのか?それは、先に述べたようにTransformerは単語(またはフレーズ)の次に来る単語(またはフレーズ)を過去の文献から予測するものであるのに対し、笑いは「不一致理論」や「おかしみの構造図」で定義されているように、次に来る単語(またはフレーズ)が予測できないものであるためである。
また、笑いは難しく、対話の中で次に来ると思っていた単語(またはフレーズ)と単純に異なる単語(またはフレーズ)が次に来ればよいだけでなく、ちょっと外した単語(またはフレーズ)が来ることによって笑いが生じると言われている。
例えば「犬はお好み焼き、たこ焼き、串カツで有名だよね」「あほちゃうか、それは大阪やろ」という対話は意味が分からず「?」となるが、「東京はお好み焼き、たこ焼き、串カツで有名だよね」「あほちゃうか、それは大阪やろ」という対話は笑いのある対話となる。
つまりは、ある程度概念が近い(ここでは土地名という概念)単語が次に来るのがよいと言われている。そこで、これを概念距離と呼ぶが、笑いを誘うある程度の概念距離はどのくらいか?を数値としてあらわす必要があると考える。
そこで、ここで紹介する漫才台本自動生成手法は,Transformerを使用したChatGPTのような自動生成手法とは異なり、フレームを用いたルールベースによる漫才台本の自動生成手法である。その中にAIの技術を用いている。
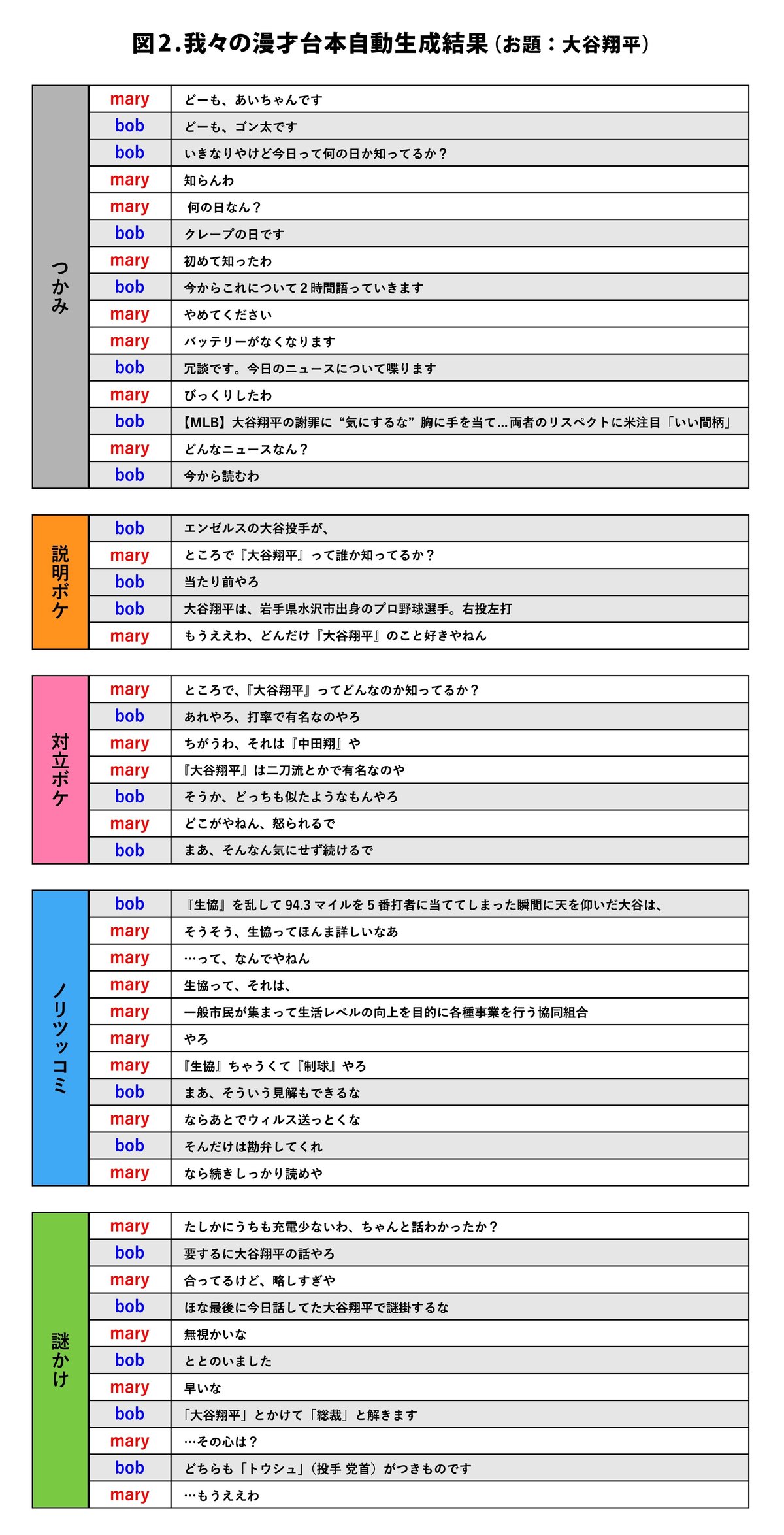
ご存じのように、漫才の中で特にしゃべくり漫才といわれる漫才は「つかみ」「本ネタ」「オチ」の3段論法になっているものが多い。我々はこのしゃべくり漫才の構成を利用し、ニュースから漫才台本を自動生成する手法を提案している。
我々の漫才台本は「つかみ」は最初のあいさつで、季節のあいさつを行う。「本ネタ」の部分はボケコンポーネントと呼ばれる、面白おかしい複数の対話からなる対話コンポーネントの組み合わせにより生成する。
ボケコンポーネントは、「言葉遊びボケ」「ノリツッコミ」「過剰ボケ」「対立ボケ」「感情ボケ」「名前列挙ボケ」「ぎなた読みボケ」等様々なボケを用意しており、漫才台本を作成するニュースにより、どのボケを採用するかを決定している。例えば対立語をもつ単語が出てきたら、対立ボケを、有名人が出てきたら人名列挙ボケを、といった具合である。
簡単に「対立ボケ」について説明する。「対立ボケ」とは「犬と猫」や「東京と大阪」等ライバルと言われている語に入れ替えるボケである。例えば
A: お好み焼き定食やたこ焼き、串カツ、かすうどんなど、有名な食べ物がたくさんあるのはどこでしょうか?
B: 馬鹿にしているのちゃうか?東京やろ、そんなのみな知ってることやろ。
A: お前はやっぱりあほやな、東京ちゃうて大阪やろ!
という感じで、単語をライバルに入れ替えること(ここでは大阪と東京)によるボケである。
このライバルの単語はAIにより決定されている。このように、各々のボケコンポーネントはAIにより単語を決定しそのフレームにはめ込んだセリフを決定している(詳細は[15][16]を参照)。
さらに「オチ」は自動生成するなぞかけで最後の締めのひと笑いを誘う。我々の生成するなぞかけは「AとかけましてCと解く、そのこころはB(B’)である」というものである。
例えば「フィギアスケート(A)とかけまして仏教(C)と解く、そのこころはどちらもえんぎ(演技(B)/縁起(B’))がつきものです。」といった感じである。
我々の生成するなぞかけはA(フィギアスケート)とよく出てくる単語B(演技)をインターネットから見つけ、Bと同音異義語のB’(縁起)を決定し、そのB’とよく出てくる単語C(仏教)をインターネットから見つけてなぞかけを作るといったものである。
このようになぞかけ生成は単純でありAIの技術を使っていない。このように現在我々の提案する漫才台本自動生成は本ネタの部分にのみAIを使用している。そして漫才台本はリアルタイムで生成する。
図2に我々の生成した漫才台本を示す。
漫才ロボットとチャットシステム
生成した漫才台本を音声合成に変換し、その漫才を披露するのは、我々の制作した漫才ロボット(図3)とチャットシステム(図4)である。


漫才ロボットは左がツッコミのあいちゃんで高さ1m、右がボケのゴン太で身長55cmである。ロボットの中には2体のロボットの発話のタイミングをコントロールすると共に、ロボットの動作を指示するPCが各々入っている。漫才ロボットの目はこのPCのディスプレイであり、セリフによって目の形が変わる。
漫才ロボットは大型のため、誰もが気軽に漫才を見ることができない。そのため、気軽に漫才を見られるようにチャットシステムも開発した。チャットシステムも左がツッコミのアイちゃん、右がボケのゴンタとなっている。
漫才ロボットの実演は[17]にてご覧いただければと思う。
おわりに
これまで我々が提案してきた漫才台本自動生成はルールベースに基づき、その中にAIが決定した単語を埋め込むことで漫才台本を生成してきた。現在我々は完全な自動生成を行うべく、あらたなロジックをTransformerベースで研究開発している。今後の研究成果に期待していただきたい。
[1]OpenAI:https://openai.com/
[2]ChatGPT:https://chat.openai.com/
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin,“Attention Is All You Need”, In Advances in Neural Information Processing Systems 30, 2017. DOI5998ś6008.
[4] 大平哲也,今野弘規,立花直子,“不安・緊張に対する笑いの効果についての研究―森田療法の予防医学への応用に関する検討―”,メンタルヘルス岡本記念財団研究助成報告集,15,pp.19–22, 2003.
[5] 西田元彦,大西憲和,"笑いと NK 細胞活性の変化について", 笑い学研究 2001年 8 巻 pp. 27-33,2001.
[6] 三宅優,横山美江,“看護ケア領域における笑いの有効性に関する文献学的考察”,日本看護科学会誌,Vol.31,No.3,pp.61-67,2011.
[7] Morishima T, Miyashiro I, et al. “Effects of laughter therapy on quality of life in patients with cancer: An open-label, randomized controlled trial,” PLoS One. 2019 Jun 27; 14(6):e0219065.
[8]笑い療法士:http://www.jshe.gr.jp/warai.html
[9]日本笑い学会:http://www.nwgk.jp/
[10] 吉田昂平, 関口理久子,"笑いの探索的研究",日本認知心理学会第3回大会, 2005
[11] 安部達雄“漫才における「フリ」「ボケ」「ツッコミ」のダイナミズム” 早稲田大学大学院文学研究科紀要第3 分冊日本文学演劇映像美術史日本語日本文化, Vol. 51, No. 28, pp. 69-79, 2006.
[12]AI 大喜利:https://page.line.me/exo9888v?openQrModal=true
[13] 藤倉将平, 小川義人, 菊池英明, "ユーモア発話の自動生成における単語間類似度導入によるユーモア受容性の向上", HAI シンポジウム, 2014.
[14] 中谷仁,岡夏樹, "ロボットの日常会話におけるユーモア生成の試み", 人工知能学会全国大会論文集 第23回,2009.
[15] Ryo Mashimo, Tomohiro Umetani, Tatsuya Kitamura and Akiyo Nadamoto, “Human-Robots Implicit Communication based on Dialogue between Robots using Automatic Generation of Funny Scenarios from Web”, In Proceedings of the 11th ACM/IEEE International Conference on Human-Robot Interaction(HRI 2016), March 7-10, Christchurch, New Zealand, 2016.
[16] 原口和貴, 青木哲, 北村達也, 梅谷智弘, 灘本明代, “人名を用いた漫才台本自動生成の提案” 第11 回データ工学と情報マネジメントに関するフォーラム(DEIM2019), C6-5, 7 pages, 2019.
[17]漫才ロボットの実演:https://www.youtube.com/watch?v=SUKzE1vV3zQ
<執筆者略歴>
灘本 明代(なだもと・あきよ)
東京理科大学理工学部卒業。複数の民間企業を経て、2002年神戸大学大学院自然科学研究科博士課程修了、博士(工学)。2002年~2008年独立行政法人情報通信研究機構、2008年甲南大学知能情報学部、2011年より現職。
この記事に関するご意見等は下記にお寄せ下さい。
chousa@tbs-mri.co.jp